
The importance of ITAM for CaaS, ESG Scope 3.1, and Cloud Cost Optimisation
- Jess Kristoffersen
- Sep 10, 2025
- 9 min read

Updated: Feb 20

“Yesterday we had 40 instances, today 80, tomorrow 400 — and the day after, back down to 60.” A customer said this to me — no drama, no complaint. Just fact. And in that fact lies the story of cloud volatility, and why ITAM has never been more critical.
Once upon a time, ITAM meant counting racks of servers, laptops on desks, and maybe a stack of software licences in a cabinet. Today, it means chasing assets that don’t even look like assets anymore. Instances that live for minutes. Containers that scale up and vanish overnight. Pipelines that run quietly until the bill arrives.
The numbers change shape, but the stakes haven’t moved:
Money — spend that balloons or evaporates depending on what’s running.
Risk — blind spots that become tomorrow’s breach.
Compliance — auditors asking for proof that doesn’t exist.
Sustainability — emissions hidden in supplier SLAs.
When your infrastructure can swing from 40 → 400 → 60 in a week, the real question isn’t who is running it, and what’s running. It’s who actually knows?
How ITAM Treats CaaS Instances
Let’s be clear: CaaS instances are assets. They may not sit on a desk, but they drive spend, carry risk, and support business services just like laptops and servers once did. Treat them as invisible, and chaos wins. Treat them as assets, and ITAM brings them under control.
The Cloud Asset Management discipline
CaaS sits inside the Cloud Asset Management family, right next to SaaS, PaaS, and IaaS. It’s not an exception — it’s a category. If you’re serious about cost, compliance, or ESG, you can’t leave containers outside the asset map.

Lifecycle management
The lifecycle hasn’t changed, only the speed. Request → Provision → Use → Change → Retire. In DevOps, that loop can run in a single sprint. Without lifecycle discipline, elasticity becomes sprawl. Idle nodes keep running. Test environments never shut down. Costs multiply in silence.
Cloud Cost Optimisation with ITAM: Contractual and Financial Governance
Every CaaS instance or subscription comes with a contract: pay-per-use, reserved capacity, licensing bundles. ITAM answers three basic but often ignored questions:
Who owns the contract?
What drives the cost, is it
consumption?
Seats?
Commits?
Are services over- or under-utilised?
Without these answers, finance just sees bills rising and falling with no story attached.
ITAM for Security & Compliance: Meeting NIS2, DORA, CIS with CaaS Control
Untracked instances aren’t only expensive — they’re dangerous. A pipeline spun up without governance can bypass security reviews, skip license checks, and leave open doors in production. ITAM provides the authoritative inventory regulators expect.
NIS2, DORA, and CIS all start from the same demand: prove what you run, and prove you control it.
ESG & sustainability
Cloud doesn’t erase emissions — it redistributes them. The provider and the customer each carry part of the reporting load:
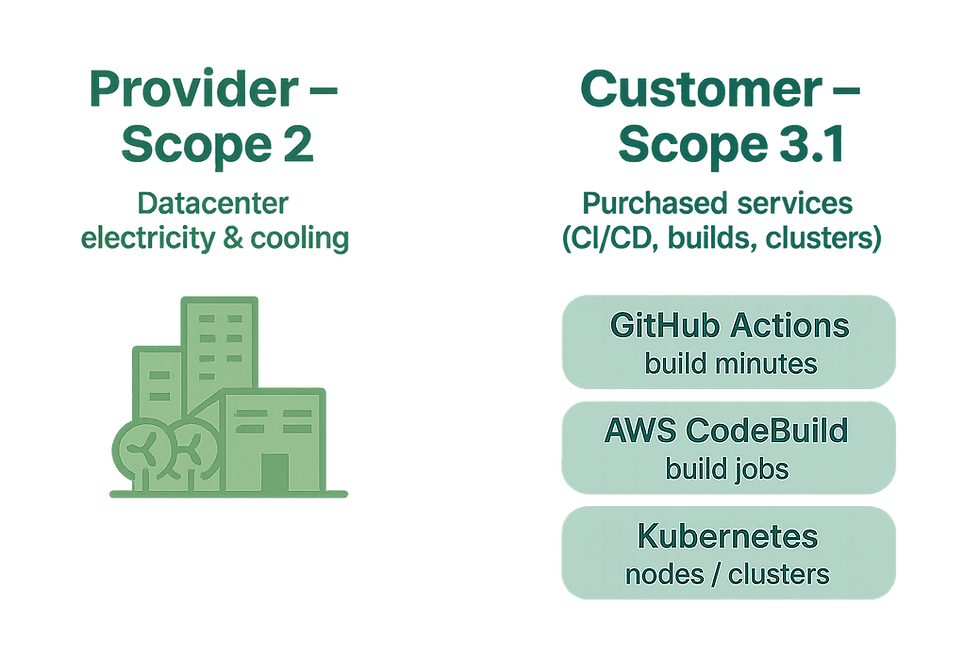
Provider responsibility (Scope 2): AWS, Microsoft, or Google report their own datacenter electricity use and cooling. That’s their Scope 2 footprint, not yours.
Customer responsibility (Scope 3.1 – Purchased Goods & Services): Every CaaS service you consume falls here. That includes:Build minutes on GitHub Actions.Code pipelines on AWS CodeBuild.Container workloads on Kubernetes/EKS.Any other “as-a-Service” container execution environment.
For you, these are purchased services. According to the GHG Protocol, all purchased IT services are part of Scope 3.1.
That means your ESG report must capture:
The quantity of services consumed (minutes, nodes, pipelines).
The contractual spend attached to those services.
The emission factors from the provider that translate usage into CO₂e.
The challenge
Most companies can’t map usage to emission factors, because they lack clean ITAM data. Without it, Scope 3 reporting becomes guesswork.
The solution
ITAM ties every CaaS instance to its contract, cost centre, and business service. That makes Scope 3.1 reporting not only possible but auditable — turning containers from invisible workloads into measurable, reportable assets.
Benefits of Managing CaaS with IT asset management
CaaS may feel invisible, but once it’s treated as an IT asset the business gains are immediate and measurable.

Cost optimisation
Cloud sprawl is one of the fastest ways to drain a budget. Idle containers run in the background. Test pipelines never get shut down. Kubernetes nodes sit half empty but still bill at full price.
ITAM puts a stop to it. By tagging instances, tracking usage, and right-sizing workloads, waste is surfaced and eliminated. Gartner research shows organisations with mature ITAM programs achieve up to 30% cost savings in year one and 5% ongoing year after year.
Operational transparency
Without ITAM, no one can answer basic questions: Who spun this up? What service depends on it? Why is this still running? A central inventory changes the game.
Suddenly, operations can map workloads to business services, troubleshoot faster, and retire environments automatically. Transparency turns firefighting into managed control.
Risk reduction
Untracked CaaS instances are a liability. They can run unpatched code, use unvetted open-source libraries, or quietly consume licenced components in violation of agreements.
ITAM exposes those blind spots. With a live inventory tied to contracts and dependencies, compliance teams know exactly what’s running, where, and under which terms. The result: fewer audit failures, fewer late-night patch scrambles, and fewer vendor disputes.
Strategic value
This is where containers stop being “just technical stuff.” Once linked through ITAM, CaaS workloads become visible in the business value chain. Finance can see costs mapped to projects.
Operations see dependencies mapped to services. ESG teams see usage mapped to emissions. Leadership sees the impact in one view. What looked like a technical swarm becomes a strategic resource.
From 40 to 400 to 60 — From Calm to Chaos to Control

“Yesterday we had 40 instances, today 80, tomorrow 400 — and the day after, back down to 60.” In that one line, my customer described the modern reality of cloud-first IT:
Volatility isn’t the exception — it’s the baseline. And that baseline is exactly where ITAM earns its relevance.
Monday: (40 instances)
The week begins with 40 workloads. A lean mix of production services and a few pipelines. On the surface, it looks stable. Finance expects spend to match the budget. Security assumes the provider patches the base infrastructure — but nobody checks whether the workloads and images running on top are actually approved or up to date. ESG teams believe emissions reporting is predictable.
The problem: Calm is deceptive. Nobody can prove who owns each instance, what business services they support, or when they should be retired. The footprint looks simple, but governance is absent.
The ITAM fix: Even at 40, ITAM establishes the baseline — mapping ownership, contracts, and dependencies. Calm is no longer just an assumption, it’s documented control.
Wednesday: (400 instances)
A new feature rollout lights up the environment. Test environments are cloned. Pipelines multiply. Kubernetes nodes auto-scale. By midweek, workloads have exploded tenfold.
The problem: Finance sees spend spike without explanation. Security can’t verify which images are approved or patched. ESG can’t tie the surge to Scope 3.1 reporting. Compliance has no evidence to show regulators.
The ITAM fix: Lifecycle governance means every request is logged and tied to a business service. Dashboards reveal who triggered the spike, what contracts it consumes, and how it impacts finance, security, and ESG. Chaos is explained instead of hidden.
Friday: (60 instances)
Most workloads are decommissioned. But not all. Forgotten staging environments linger. Idle nodes continue billing. A few unpatched containers stay alive in the shadows.
The problem: Finance expects costs to drop, but ghost workloads keep spend elevated. Security faces risk from forgotten containers. ESG reporting drifts off course.
The ITAM fix: Automated decommissioning closes the loop. Every instance is tied to a lifecycle event. Old workloads retire on schedule. Finance sees spend normalize. Security patches what remains. ESG reporting reflects reality.
By week’s end, the company is back at 60 instances. The volatility didn’t disappear — but with ITAM, it’s no longer chaos. It’s agility, governed and explained.
From Business Volatility to Technical Reality — Where ITAM Meets DevOps
The swings from 40 to 400 to 60 make headlines in the boardroom. But those numbers don’t appear out of thin air. They’re the sum of real pipelines, real containers, and real build jobs running — or forgotten — inside DevOps.

This is where the story shifts. What looks like volatility on a graph is actually dozens of small technical decisions happening every day:
A developer spins up a new build environment.
A staging cluster scales without a shutdown script.
A pipeline clones itself because testing needed speed.
Individually, these choices feel harmless. Collectively, they create the swings that finance can’t explain, compliance can’t audit, and ESG can’t report.
And this is where ITAM earns its credibility with engineers, not just executives. By embedding lifecycle checks, contract visibility, and change governance into DevOps workflows, ITAM doesn’t slow teams down — it gives the organization visibility over what’s really happening.
The volatility story of the boardroom is mirrored in the daily choices of DevOps. To see how it plays out, let’s follow one product team and watch how ITAM turns chaos into control.
The DevOps Scenario — ITAM in Practice
Picture a product team running everything in the cloud:
GitHub Actions for CI/CD pipelines.
AWS CodeBuild for testing.
Kubernetes clusters on AWS EKS for runtime.
No laptops to track, no servers on the floor — everything runs as code. It’s fast, flexible, and elastic. Until it isn’t.
Where the problems appear:
A developer spins up a new build environment — nobody tracks it.
Kubernetes nodes scale up overnight — costs jump.
Pipelines pull in open-source libraries — compliance risk creeps in.

Individually, these decisions feel harmless. Collectively, they create the volatility that finance can’t explain, security can’t verify, and ESG can’t report.
Where ITAM makes the difference:
Lifecycle control — every request is logged, tied to an owner, and linked to a business service.
Financial governance — costs are traced back to teams and projects, not lost in a generic cloud bill.
Optimisation — underutilized nodes and idle builds are flagged before they drain budget.
Compliance — libraries, versions, and contracts are tracked, so risk is managed.
The business outcome:
Cloud spend drops by 30% in year one.
Audits move from scramble to ready.
Incidents resolve faster because dependencies are visible.
Finance, Security, and ESG finally share the same source of truth.
What looked like invisible workloads becomes visible and governed. The volatility of “40 → 400 → 60” no longer terrifies the boardroom — because DevOps is under control, not out of sight.
How The 5-STEP Model from Chloris Consulting Group Works
Volatility and complexity are universal. What separates companies that wrestle with it from those that master it isn’t luck — it’s structure. At Chloris Group, that structure is the 5-STEP Model. It’s how we take cloud swings, CaaS sprawl, and audit gaps, and turn them into a governed, predictable system.

Step 1: Discovery
Every engagement starts with clarity. We don’t just count workloads — we expose the lifecycle behind them. How are containers requested? Who approves them? Which business service do they support? Without Discovery, everything else is guesswork. With it, volatility finally has a map.
Step 2:
Analysis Facts become insight. Discovery shows what exists. Analysis shows where it fails. We map gaps to NIS2, DORA, ISO27001. We call out underutilized spend, unowned workloads, and Scope 3.1 blind spots. Volatility stops being noise and starts making sense.
Step 3: Direction
Insight must become action. Direction means prioritizing fixes: which lifecycle gaps must close first, which guardrails prevent the next spike from 40 → 400. We build a roadmap that aligns finance, security, and ESG teams so everyone pulls in the same direction.
Step 4: Execution
Roadmaps don’t live on slides — they have to run in practice. Execution is where ownership is embedded, dashboards are built, automated decommissions are turned on, and reporting flows into finance and sustainability systems. Elasticity continues. But this time, it answers to you.
Step 5: Anchoring
The final step is what makes change permanent. Governance forums, reporting cadences, and predictive models are put in place so ITAM doesn’t slip back into a one-off project. Anchoring turns lifecycle governance into culture. Volatility is no longer a shock; it’s just part of how the business operates.
By the end of the 5-STEP journey, organizations don’t just “do ITAM.” They have:
A single source of truth for all assets — containers included.
Lifecycle processes that close cost and compliance gaps.
ESG reporting grounded in evidence, not estimates.
Governance structures that sustain control year after year.
It’s the difference between reacting to cloud chaos and leading with cloud clarity.
Conclusion — Why ITAM Still Matters in a CaaS World
Some still argue IT Asset Management belongs to the on-prem era. That once we left racks of servers and piles of laptops behind, ITAM lost its purpose. But the evidence is undeniable:
Cloud services are still assets. They still cost money. They still carry risk. They still underpin compliance, security, and ESG.
What’s changed isn’t the need — it’s the form. Instances, containers, pipelines, and subscriptions have replaced the hardware, but the stakes remain the same.
Without ITAM, volatility is chaos. Finance sees bills rise and fall without explanation. Security faces workloads nobody can trace. Compliance teams scramble when auditors arrive. ESG reports rely on supplier estimates and best guesses.
With ITAM, volatility becomes agility. Every workload is tied to an owner, a contract, and a lifecycle. Finance knows where spend comes from. Security sees what’s approved and patched. Compliance can deliver evidence. ESG reporting is traceable to Scope 3.1.
The swing from 40 → 400 → 60 no longer feels like a rollercoaster. It becomes just another cycle — tracked, explained, and governed. That’s why ITAM isn’t obsolete in the cloud age. It’s indispensable.
Volatility Is Inevitable. Chaos Isn’t.
If your cloud spend feels unpredictable, if resources appear faster than finance can track, if ESG reporting leans on estimates, or if every audit feels like a scramble — that’s not “just the cloud.” That’s the absence of ITAM.
IT Asset Management is the anchor in a world of elasticity. It makes costs transparent, compliance verifiable, ESG data real, and security defensible. It turns volatility from chaos into agility.
At Chloris Group, we help organizations move from firefighting to foresight. We use the 5-STEP Model to bring order to instances, containers, and pipelines — so you can scale without losing control.
So the next time your business swings from 40 → 400 → 60 in a single week, ask yourself: will that feel like chaos, or agility?
If you want the answer to be agility, don’t wait for the next swing to 400. Let’s talk before chaos sends you the bill.


Comments